











As machine learning engineers, we continually strive to push the boundaries of what is possible with artificial intelligence. One of the most recent advancements in this field is the development of large language models, such as BERT, GPT, ChatGPT, and other Large Language Models (LLMs). These models have proven to be incredibly effective at natural language processing tasks, largely due to the attention mechanism, a crucial component that enables them to selectively focus on specific parts of the input sequence when making predictions.
What is the Attention Mechanism?
In essence, the attention mechanism allows the model to concentrate on particular parts of a given input sequence — mimicking the cognitive attention found in humans and other living beings — when making predictions. This is especially important in natural language processing, where the meaning of a sentence can heavily rely on the context in which it is used. By selectively focusing on different parts of the input, the model can better understand the relationships between words and phrases, resulting in more accurate predictions.
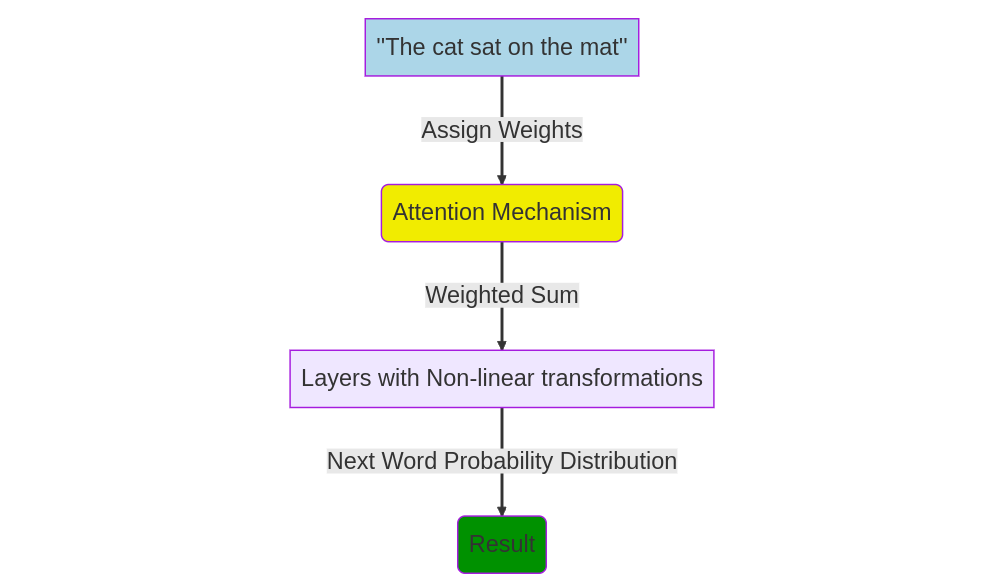
To grasp how the attention mechanism works, let’s consider a simple example. Suppose we have a sentence like “The cat sat on the mat.” In order to predict the next word in the sequence, the model needs to understand the relationship between “cat” and “mat”. One way to achieve this is by using a technique called self-attention, where the model examines all the words in the sentence and assigns each one a weight based on its relevance to predicting the next word. In this case, the model might assign a high weight to “cat” and “mat”, since they are both nouns and are in close proximity to each other.
Once the model has assigned weights to each word, it uses them to compute a weighted sum of the input sequence. This weighted sum is then passed through a series of layers, each applying a non-linear transformation to the input. The final output of the model is a probability distribution over all possible next words, based on the input sequence and the weights assigned by the attention mechanism.
It’s important to note that this is a simplified explanation of how the attention mechanism works. In reality, there are numerous variations and refinements that have been developed over the years. For instance, some models use multi-head attention, where the input sequence is divided into multiple parts, and each part is attended to separately. This approach helps the model capture different types of relationships between words and phrases, leading to even better performance on natural language processing tasks.
Another key aspect of the attention mechanism is its ability to handle variable-length input sequences. In natural language processing, sentences can vary in length, and traditional machine learning models struggle to cope with this variability. However, by using the attention mechanism, large language models can selectively focus on different parts of the input sequence, regardless of its length. This makes them much more adaptable and powerful than previous generations of models.
Real-world Applications
In real-world applications, the attention mechanism has proven to be a game-changer.
For example, in chatbots, the attention mechanism is used to understand user input by concentrating on the most relevant parts of the conversation. This enables the chatbot to provide more accurate and pertinent responses. In language translation models, the attention mechanism is used to enhance accuracy by selectively focusing on the most crucial parts of the input and output sequences.
To help readers visualize how the attention mechanism works, an intuitive diagram illustrating how the attention weights are assigned to each word in a sentence is included below:
It’s also worth mentioning that there are different types of attention mechanisms, each with its own advantages and disadvantages. For instance, additive attention is a popular variation that allows the model to learn the importance of each word pair by adding them together. Multiplicative attention, on the other hand, enables the model to learn the importance of each word pair by multiplying them together. Understanding the differences between these variations can help machine learning engineers choose the most suitable approach for their specific use case.
Conclusion
In conclusion, the attention mechanism is a vital component of contemporary large language models like ChatGPT. By allowing the model to selectively focus on different parts of the input sequence, it can better understand the relationships between words and phrases, leading to more accurate predictions. This article provides a comprehensive overview of the attention mechanism and its role in natural language processing, complete with real-world examples, visuals, and information on different variations.

