


Introduction
Feature selection is a critical process in machine learning pipelines to improve model performance and generalization. It involves identifying and selecting the most relevant features in your dataset that are most predictive of the target variable.
Applying feature selection provides several key benefits:
- Reduces overfitting by removing redundant, irrelevant or noisy features.
- Improves model accuracy by focusing on most informative features.
- Speeds up training time by reducing dimensionality.
The scikit-learn Python library provides a suite of useful feature selection techniques and utilities to pick the best features for your model. Key options in scikit-learn include:
- Statistical tests like ANOVA and chi-squared.
- Recursive feature elimination.
- Feature importance from tree-based models.
- Model-based selection through regularization.
Applying the right feature selection approach for your dataset and use case is an important part of the machine learning workflow. Scikit-learn provides a variety of tools to identify and select the most impactful features for building effective models.
This article provides an overview of the main feature selection techniques available in scikit-learn.
Univariate Selection
Univariate selection evaluates each feature individually to determine how predictive it is of the target variable. This simplifies the selection process and interpretation compared to multivariate approaches. However, it ignores potential interactions between features.
Scikit-learn’s SelectKBest implements univariate filtering based on statistical tests like ANOVA, chi-squared, and correlation coefficients. It removes all but the k highest scoring features based on the chosen metric. This provides a straightforward way to select impactful individual features.
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
selector = SelectKBest(score_func=f_classif, k=10)
selector.fit(X, y)
X_selected = selector.transform(X)
Recursive Feature Elimination
Recursive feature elimination (RFE) takes a model-based approach to feature selection. It trains a model, ranks features by importance, and prunes the weakest features recursively until the desired number remains.
The RFE and RFECV classes in scikit-learn provide automated RFE. This wraps any estimator model and provides recursive feature ranking and elimination. RFE can be effective at eliminating redundant features, but can be computationally expensive.
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
rfe = RFE(estimator=LogisticRegression(), n_features_to_select=10)
rfe.fit(X, y)
X_rfe = rfe.transform(X)
Feature Importance
Feature importance measures the relevance of features based on how they contribute to a model’s predictions. Importance values are automatically calculated for certain models like tree-based estimators.
Random forests, gradient boosting machines, and other tree-based estimators in scikit-learn have built-in feature importance calculation. This provides a simple, integrated way to identify key features driving the model without additional processing.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X, y)
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
features = X.columns
for f in range(X.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, features[f], importances[indices[f]]))
Model-Based Selection
Model-based selection uses the model coefficients or changes in model performance to select important features. Techniques like L1 regularization naturally perform feature selection by inducing sparsity in linear models.
Scikit-learn’s SelectFromModel meta-transformer facilitates model-based selection. By wrapping models like L1 regularized regression, unimportant features can be automatically filtered during training. Model-based selection provides an integrated approach combining feature selection and modeling.
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty="l1", C=0.1)
sfm = SelectFromModel(lr)
sfm.fit(X, y)
X_l1 = sfm.transform(X)
Summary
Feature selection is a crucial step in machine learning to improve model performance. The scikit-learn Python library provides several techniques for selecting the most relevant features in your data.
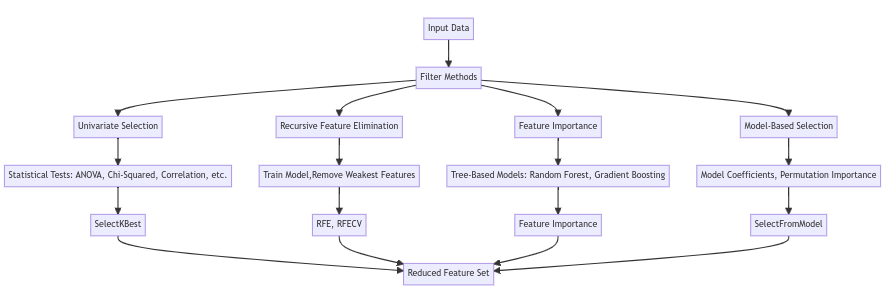
Key feature selection methods in scikit-learn include:
- Univariate selection like SelectKBest to evaluate and rank individual features.
- Recursive feature elimination (RFE) to recursively prune weak features.
- Feature importance from tree-based models like random forests.
- Model-based selection through techniques like L1 regularization that induce sparsity.
Applying feature selection removes redundant, irrelevant and noisy features. This leads to better generalization, faster training times, and improved model accuracy by reducing overfitting. The right feature selection approach depends on your data and use case.
Overall, leveraging scikit-learn’s feature selection utilities is a best practice in machine learning. This allows focusing models on the most informative features and avoiding pitfalls like the curse of dimensionality.


